
Google advertises that “reduced latency” is a primary advantage of Apigee Hybrid compared to Apigee X. The questions we keep hearing about this are “by how much?” and “is it worth the extra effort?”
Apigee X is significantly simpler to operate, while running Apigee Hybrid requires strong infrastructure capability and skills that some teams and organisations don’t have, don’t want, or don’t want to spend the time on.
We’ve put together an experiment to provide data to compare the performance and latency of Apigee X against Apigee Hybrid. You can skip to the end for the key findings.
Background: Apigee X vs Apigee Hybrid
Apigee X is the SaaS offering, Apigee Private Cloud is the on-premise offering, and Apigee Hybrid is part SaaS/part on-premise. As described in the Hybrid documentation, Google hosts the “management plane” (admin/developer UI, management API, analytics) and you host the “runtime plane” (where API traffic is processed) using your own Kubernetes cluster.
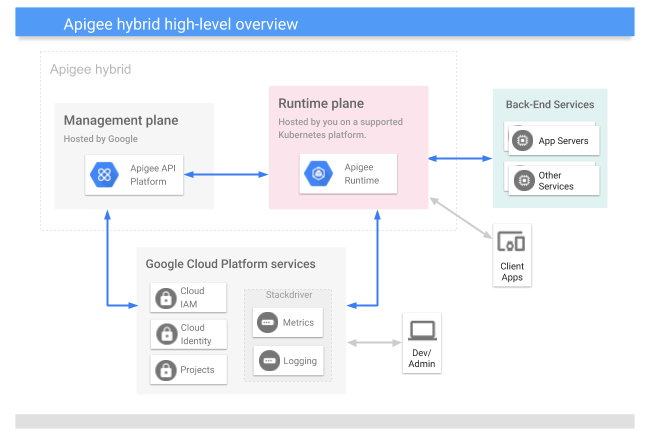
The Hybrid management plane is largely identical between X and Hybrid. Developers and administrators see the same UI with the same layout and features.
There are subtle differences, but probably the only one that your team will notice is the “hybrid” tag when selecting the organisation.
There are a wide array of supported Kubernetes platforms you can choose to host the runtime plane on, so you should be able to co-locate your API Gateway and backends almost anywhere.
The installation instructions largely target GCP, but with the right expertise it’s a snap to get running on other supported platforms.
Setup and Method
Most APIs are not restricted by CPU, RAM or storage; instead network latency is the main difference between a sluggish and a responsive API.
There are lots of ways that latency can be added during a real API call, such as by call-outs to authentication and authorisation services, threat scanning, and poorly implemented logging. Latency can also be reduced through caching.
A real API has too many dimensions to simply isolate the difference between X and Hybrid, so we’ve created an unrealistically minimal API pipeline to gather the data. In Apigee we created the most basic “reverse proxy” possible; there’s no authentication or any other flow through Apigee.
We’re assuming that you would deploy the same pipeline and provision enough capacity for the Message Processors, which makes the processing time a fixed constant in our model. We’ve built a single Node.js backend that generates a hash from a POST request and sends back the result.
This allows us to use a unique payload and response for every request (preventing any caching interfering with the results) and should provide consistent backend processing time for all requests.
While Apigee does measure latency, we wanted to make sure that our measurements were impartial and took into account external clients (Apigee can’t measure the time from the client to the gateway and back).
To get full round-trip-time measurements we created another API container, this time using Python’s FastAPI. While FastAPI is asynchronous, the synchronous requests module was used for the measurements to minimise any time waiting to process the response on the client side.
Multiple Apigee instances were set up: Apigee X, a Hybrid instance with runtime components on GCP, and a Hybrid instance with runtime components on AWS. GCP and AWS each hosted the backend API that was exposed directly and via all three Apigee instances.
Exposing the API directly allowed us to collect baseline data for the round trip time without any gateway. The client API was hosted on GCP and AWS, and also on the local machine running the test in order to gather data for a client using typical Australian NBN.

With client and backend containers ready, Apigee X setup and Hybrid installed we just needed a way to orchestrate the test and collate all of the results. Thankfully a short Python script is all that it took to coordinate these tasks.
The code for all of these artefacts is available on GitHub.
Results
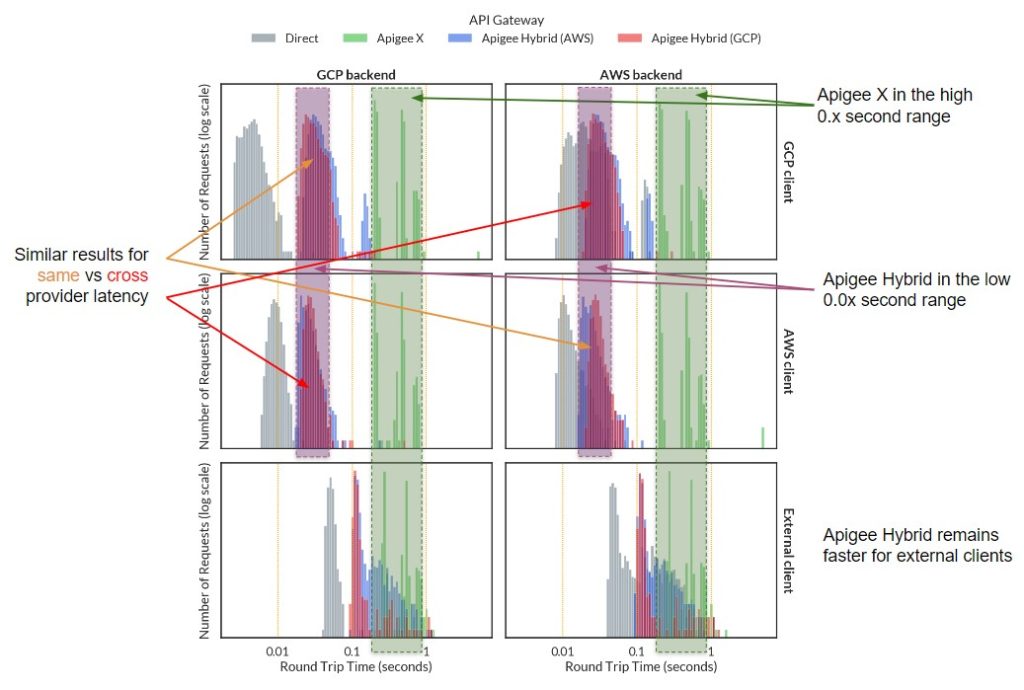
The data has been broken into 6 sections depending on where the client request originates from and where the backend API is hosted. Each section has four datasets depending on what type of API gateway brokered the request.
The “direct” API gateway shows the client connecting directly to the backend and represents the network baseline for the request; it can’t get there any faster, and it shows how much variability is caused by the network route alone.
This is particularly useful when comparing the difference between internal clients (which can quickly route to the gateway) and external clients (which need to travel multiple network hops to reach the gateway).
There are three orders of magnitude for time and requests, so the data is presented in log scale for both axes. The absolute number of requests is not as important as their distribution over time, which can be seen in the shapes created by each set of columns.
Narrower peaks show more consistent response times. An ideal API gateway would not add variability to the response time, so it should be the same shape as the direct path. The closer the peaks are to the “direct” peak, the less latency that is added by the API gateway.
Apigee X consistently returns results in the high tenths of a second range, though there are a few outliers in the whole seconds range.
The double peak in the data is unusual and is probably caused by the same Apigee X gateway handling many other customer’s traffic as well.
The peaks don’t shift with the baseline direct data because clients must always route to Google’s global address, which should always take about the same amount of time.
Apigee Hybrid does shift with the baseline direct data, though the peaks converge as the baseline shifts right indicating that Hybrid is adding a consistent few hundredths of a second to the overall round trip time.
For the low traffic volume in this test the peaks are shaped very similar to the baseline direct data.
Discussion
While six sections of the data are presented, they can be simplified into two categories: those for consumers on your internal network (top four graphs), and those coming from outside your organisation (bottom two graphs).
When the consumer is outside the network, it has to reach the API gateway first, which can be slow for consumers with network congestion or poor reception.
Where your API gateway is hosted doesn’t make much of a difference to this first hop compared to all of the other variables involved.
In practice, the outcome is that Apigee Hybrid and Apigee X latencies start to converge, though Hybrid is still significantly faster for the reliable external client used in this experiment.
Why are we categorising cross-service requests for AWS and GCP as “internal”?
The unexpected exception to the “external” behaviour described above when bridging between AWS and GCP (blue bars in top left, red bars in middle right). Mixing AWS and GCP as client, gateway and/or backend doesn’t make a significant difference to the latency.
It appears that the peering between AWS and GCP within equivalent regions provides latencies similar to if they were entirely contained within one or the other’s network.
This is a good result if you are a multi-cloud organisation, or your consumers are other services hosted by the major providers. These results likely vary between regions and between other service providers.
The most notable results are for the internal consumers where Hybrid provides a 10x improvement to latency.
While we are talking about hundredths of a second versus tenths of a second, as mentioned earlier there may be multiple callouts to backend APIs for each request received, so those fractions do add up.
In practice the distinction isn’t binary, though. Your consumers likely need to authenticate with your Identity Provider (IdP).
Your IdP may be self-hosted on your internal network and provide authentication for external consumers, or you may have a third party IdP in another region authenticating your internal consumers.
A solid understanding of your API pipeline is required to realise the full expected performance gains demonstrated here.
Key Findings
The key findings are summarised as:
- For internal APIs, that is when the consumer and backend are on the same network, Apigee Hybrid provides a 10x improvement to latency compared to Apigee X.
- Clients and backends that are hosted across well connected cloud providers in equivalent regions may see this 10x improvement as well.
- Apigee Hybrid is faster than Apigee X for external consumers, but the improvement is less significant due to the additional network hops required to reach the gateway.